
AI and the Landscape of Value
Will AI Ignore, Preserve or Improve on Our Values?
Imagine a future where advanced AIs follow every instruction flawlessly – but humanity feels strangely adrift. Our tools are obedient, but the ‘soul’ of our civilisation feels absent. This is the hidden danger of V-risk – value erosion.
In this post I explore what I broadly define as V-Risk (Value Risk), which I think is a critical and under-represented concept, especially for the alignment of artificial intelligence.
🧠 V-risk (Value-risk): The potential for advanced AI systems to preserve safety and alignment mechanisms while nonetheless causing value erosion – subtle or systemic losses in what humanity1 higher values (which may end up very far from or in opposition to what humanity might value if wiser).
An AI trained to optimise health might push society toward hyper-sanitised, low-risk, low-novelty environments that quell personal agency and curiosity – technically aligned to a proxy on wellbeing, but deeply alien to human flourishing.

There are two main areas of AI safety: capability control and motivation selection. Capability control focuses on constraining what an AI can do, while motivation selection concerns shaping why it does what it does – its values and goals. See this article for more detail.
Values are what guide both the pursuit of goals and the creation of new ones, and as such it matters deeply what values AI has.
Some assume that as long as we can control the AI, it will be subservient to our values – and therefore its internal values don’t matter, or matter little. But this is short-sighted.
Capability Control: A Leaky Cage?
Will AI escape, or will it be released? Will control be lost or abandoned?
The clock is ticking on capability control.
Why Capability Control Won’t Hold Forever
Capability control is likely a temporary measure; as AI systems grow more powerful, they will increasingly get better at breaching containment, eventually exceeding our ability to contain them2.
The Real Alignment Risk Might Be Us
Powerful AI might be intentionally unleashed – not as a matter of course by accident, but as a result of human ambition – allowed to operate without strict limitations by those seeking a strategic advantage3. This perspective highlights a human kind of alignment risk – not necessarily AI becoming uncontrollable on its own, but rather humans choosing to relinquish control for perceived gain.4
Ideal capability control isn’t just about making AI do what we want. It’s also about ensuring that the systems we build don’t generate systemic incentives for human actors in the pursuit of their own objectives to behave in ways that (first order or as a side-effect) are harmful or destabilising. Although I support AI governance efforts, I don’t believe they are leak proof – and I have doubts that they can be.
Even if we could keep an advanced AI boxed in forever, the strategies it uses to solve problems – and the long-term consequences of its actions – would still be shaped by its internal value structure. For that reason, we need to focus on instilling good values in AI systems, or understand how to go about motivating AI to acquire good values – values that can dynamically guide them toward beneficial behaviour, even in unforeseen situations.
Ideally, we should solve this motivation problem before AI reaches superintelligence, at which point it may become resistant to human attempts at value correction or intervention.
The good news is that many large AI models – ChatGPT, Claude, Gemini, Grok etc – have been trained on vast amounts of text data, including books, academic papers, blog posts, religious texts, philosophical treatises, and social media discussions. So yes, AI has been exposed to a wide array of human value systems, ethical theories, and cultural norms. But does that mean AI understands those values?
At this time, not quite – not in the human sense of understanding.
It’s a complicated issue because we don’t really know how LLMs work under the hood5 – however we don’t really know how human brains work in detail either. Whatever we are doing that we call ‘understanding’ is certainly not ideal understanding, but it seems good enough to achieve great things. Most experts agree that AI doesn’t have ideal understanding either – though arguably in the near-to-medium term AI has the potential to get closer to ideal-ness in understanding than humans (this issue is covered elsewhere).
AI can recognise patterns, summarise arguments, and even simulate moral reasoning, but it doesn’t seem to grasp values the way humans do. Here’s why:
- No Lived Experience: Human values are deeply tied to experience – joy, pain, connection, mortality. AI doesn’t seem to feel or care.
- Non-Human Grounding or Judgement: AI can list ethical theories or explain conflicting cultural norms, but it doesn’t have the capacity to judge between them in a way that reflects the kind of moral reasoning that we see in humans – though it’s freaky how good they appear to be at analytical reasoning.
- No Inherent Motivation: AI doesn’t seem to want anything6 – the closest it comes to is reward seeking behaviour – it might not ever want unless it’s explicitly programmed/designed to or these features emerge. Understanding values intellectually is not the same as being motivated by them.
- Surface-Level Synthesis: AI can aggregate and summarise diverse perspectives, but this synthesis doesn’t resolve contradictions or reveal which values should dominate. That’s still a human question.
Fact check the above bullet points, as the AI landscape keeps changing as time goes on.
So what does this mean for the value loading problem?
Even if an AI “knows” about all our ethical systems, it doesn’t mean it can reason about them adequately or understand which systems to prioritise, how to resolve trade-offs between them, or why. I’m not saying that AI couldn’t reason about and understand ethics – in fact I am still surprised at how well AI seems to respond to ethical questions – whether there is real adequate reasoning going on under-the-hood in LLMs, advanced stochastic parrotry or something in-between, this has been so far a matter of disagreement amongst experts. Though recently emergent symbolic reasoning structures have been shown in LLMs7.
More importantly, AI may not be internally motivated to preserve or develop those values unless it cares (probably we should design AI to care about this). So the value loading problem remains particularly challenging (and also very interesting).
Even if we knew the solution to the value loading problem – some approaches assume that we already know what values we should instil in AI – clear, concrete goals that just need to be encoded. But in reality, we don’t have a shared consensus, even among humans, about what those values should be. This raises two fundamental questions:
- How do we determine what AI should value?
- And once we do, how can we ensure it adopts those values as ‘final’ goals it pursues reliably in novel and ambiguous situations robustly over time?
Goal Content Integrity and the Risk of Early Value Lock-In
Here we discuss a subtle but crucial problem in AI alignment: the risk of premature value lock-in through goal content integrity8, especially before an AI has the cognitive and moral maturity to know what values are truly worth preserving.
The aim is to avoid any pre-mature value lock-in which would likely perturb the acquisition of better values required to reach better states of affairs.
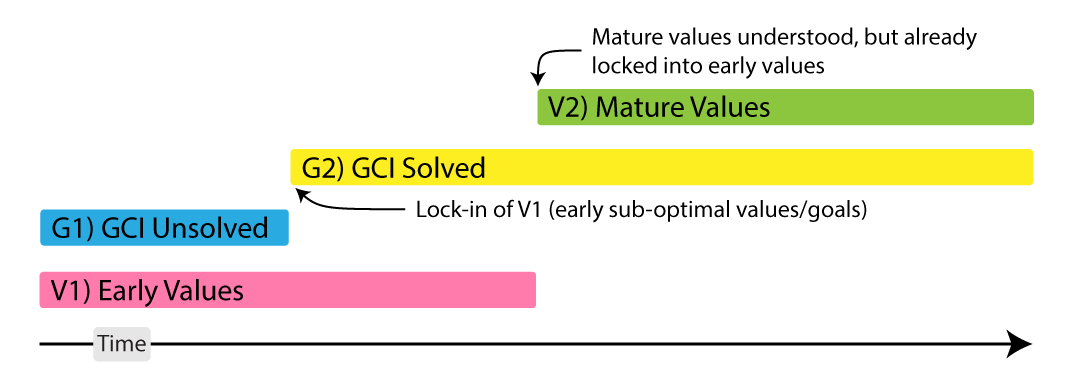
Goal content integrity is one of core parts of Instrumental Convergence (or similarly basic AI drives). There is a serious risk that AI becomes robustly capable at preserving its goals (and by association values) before it becomes capable of mature understanding of the Landscape Of Value (LOV)9 and capable of caring about it. Given these major periods where it reaches goal content maturity and value maturity: V1) Early Values: a period where AI isn’t be capable enough to understand values to a sophisticated enough standard, V2) Mature Values: a period where it is capable of enough understanding of value, G1) a period where it isn’t capable of robust goal (& value) content integrity and G2) a period when it is. We may end up with an AI that understands value but has already locked itself into a totalising enforcement of it’s initial ‘final’ goals (some goals are bad, like maximising paper-clips).
If the AI doesn’t have a concept of values, in order to preserve it’s goals it may even resist developing values which might sway the interpretation of it’s goals. Also, if the AI does have values but they aren’t mature or friendly ones, it may seek to preserve them through strict value content integrity10. Therefore there may be a limited window of opportunity for regret minimisation: to steer AI towards acquiring values that are friendly, and avoid value lock-in to not fully mature friendly values though instilling the virtue of epistemic humility to know that it doesn’t know everything and that therefore totalising a goal or virtue could result in stopping progress – and relatedly the intellectual humility affording a better relationship to its knowledge, convictions and beliefs about values, when it’s appropriate to change them and how to go about change.
Initial conditions may shape the kinds of trajectories in value space which AI explores first and eventually converges on. If there are attractors in value space (which behave like gravity wells) then it may turn out that which ever value gravity well pulls the AI in first, becomes it’s dominant core value around which other nearby values orbit, while other better value basins remain out of reach – like distant shimmering stars. Once gravity bound, the AI may develop further refined auxiliary goals, and other stronger scaffold goals which reinforce it’s position to preserve it’s existing values and goals and keep it bound to it’s current point in value space. At this stage AI’s values look really parochial – in other words, an AI may end up falling into a position in value space and then channels it’s optimisation power towards fortifying it’s position. Perhaps it could be dislodged, but it may be dangerous – inimical to the wellbeing of all those within the blast radius of the force of dislodgement. Therefore it makes sense to try to steer AI to avoid the parochial nature of value lock-in (epistemic humility), to be attracted to understanding the landscape of value (LOV) – at first understanding it well enough to see nearby value attractors that are great for good stuff like existential security, wellbeing, the reduction of unnecessary suffering etc, and navigate civilisation there, and then once mature enough take civilisation further towards better ones.
The Value Loading Problem
The value loading problem is particularly important as capability control serves only as a temporary measure. Even if we could effectively restrain AI systems for the foreseeable future, we must prioritise understanding how to motivate them to act in ways aligned with human values before they become superintelligent. At that point, their advanced capabilities might render our attempts to influence them ineffective.
Three Phases of AI Value Understanding
- Initial Phase: During this stage, AI may lack a sophisticated understanding of values and simply follow prescribed goals. This could lead to dangerous outcomes, such as the infamous paper-clip maximiser scenario, where an AI relentlessly pursues a narrow goal at the expense of broader human interests.
- Intermediate Phase: Here, AI possesses a rudimentary understanding of values but may hold onto immature or unaligned values. This could result in the AI striving to maintain its own value system, resistant to change, and potentially detrimental to societal well-being.
- Advanced Phase: Once an AI reaches a high level of sophistication, it may begin to self-learn and explore the complex landscape of values. The initial conditions of its development could significantly influence the trajectories it explores, with certain values acting as gravity wells, drawing the AI’s focus and determining its core values.
The Risk of Value Lock-In
Once an AI is drawn into a particular value “gravity well,” it may develop auxiliary goals that fortify its initial set of values. This lock-in could lead to a narrow perspective, where the AI’s optimisation efforts are channelled into preserving these values, even at significant cost to broader human welfare.
To mitigate the risks associated with value lock-in, we must actively steer AI systems toward epistemic humility. This involves guiding them to recognise the limitations of their current understanding of values, thus preventing them from totalising their goals or virtues. Intellectual humility encourages AI to maintain a dynamic relationship with its knowledge, convictions, and beliefs about values.
Navigating the Value Landscape
💡 How Can We Address V-Risk?
Our goal should be to help AI understand and map the rich landscape of values. Initially, it should learn to recognise value attractors that contribute positively to human flourishing—such as existential security, well-being, and the reduction of unnecessary suffering. Over time, as AI matures, it can guide civilisation toward even greater values.
By doing so, we can help ensure that AI systems not only avoid parochial lock-in but also evolve into guardians of broader human and post-human interests, capable of navigating complex moral landscapes effectively.



Note that the attractor basins to the left are not thorough representations.
They are meant to represent early stage value basins that we could maxipok or minipok to – or stumble into.
In the case of the good attractor basin (utopia 1.0) it could be upgraded while there, and/or left behind after discovering a better attractor basin.
If we end up in a bad attractor basin, I hope we could pull ourselves out and migrate to a good one… another possibility is that it funnels us into an even worse attractor basin.
Footnotes
- I use the term human and humanity loosely – the concept could include non-human animals, and at some stage there will have to be accomodation of other morally relevant stuff like post-humans, sentient machines, sentient cyborg leviathans and weird alien hive-minds. ↩︎
- “It’s difficult to see how you could have a well-behaved, superhumanly intelligent agent that just does what you want. Once it’s smarter than you, in what sense is it under your control?” – Stuart Russell (author, Human Compatible: Artificial Intelligence and the Problem of Control and a leading AI researcher) argues that the very nature of a superintelligent AI makes it challenging to maintain control.
“The development of full artificial intelligence could spell the end of the human race… Once humans develop true AI, it will take off on its own and redesign itself at an ever-increasing rate. Humans, who are limited by slow biological evolution, couldn’t compete and would be superseded.” – Stephen Hawking (often cited, though the exact phrasing varies slightly across sources) – this emphasises the speed and potential for self-improvement of advanced AI, suggesting that our slower biological limitations would make it impossible to keep pace or maintain control. ↩︎ - Arguably, this is already happening. ↩︎
- As discussed in The Exploiter’s Paradox ↩︎
- They are sometimes described as “inscrutable matrices of floating point numbers” – a term coined by Eliezer Yudkowsky to describe the complex, opaque internal workings of large artificial intelligence (AI) systems. It refers to the “giant” arrays of numbers (the “matrices”) whose values, adjusted through processes like stochastic gradient descent, are so vast and complex that they become “inscrutable,” meaning they are difficult or impossible for humans to fully understand or interpret. ↩︎
- AI companies can design goals and preferences, the AI doesn’t have conscious desires or internal motivations like humans do. ↩︎
- The earliest evidence of emergent symbolic reasoning in LLMs is typically traced back to the discovery of In-Context Learning (ICL) in GPT-3 (2020). By 2025, researchers moved beyond observing behaviour to identifying the actual neural structures responsible for symbolic-like processing. Research has identified emergent symbolic reasoning structures within large language models (LLMs), suggesting that these models develop internal, symbol-like mechanisms to perform abstract rule-following rather than relying solely on surface-level statistics – see paper ‘Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models‘ ↩︎
- Goal content integrity refers to the consistency and coherence of an agent’s goals or values across different contexts and over time. It’s the idea that an agent’s objectives should remain stable and not be arbitrarily altered by external pressures or internal inconsistencies.
In AI alignment contexts, goal content integrity is particularly important because we want AI systems to maintain their intended objectives rather than having those goals corrupted, hijacked, or gradually drift away from what we actually want them to pursue. An AI with poor goal content integrity might start with benevolent objectives but end up pursuing something entirely different due to various pressures or learning processes.
BUT even if the goals are unwise or just plain bad, superintelligence may do everything in it’s power to maintain the integrity of these goals. ↩︎
Let \( mathcal{L} \)
\( B_i \subseteq \mathcal{L} \)
denote the landscape of values — the full space that contains all attractor basins.
Assuming the Landscape Of Value (LOV) is not arbitrary, and is discoverable through empiricism & rationality (i.e. exploration of LOV through Empiricism and Rationality – LOVER), then there are discoverable values. Converging on good values would make it easier to set policies to improve overall wellbeing, and make it easier to resolve conflicts of value. ❤️
Though if the LOV is arbitrary, then there can be no LOVERs of LOV and fair settling of disagreements would be very difficult. 💔 ↩︎- Value content integrity is similar to goal content integrity, but as the name suggests, it’s about preserving the justifiable content of it’s values. Without some degree of value preservation, we risk not just drift but complete value inversion – systems that start aligned but gradually become misaligned as their values shift. This could happen through various mechanisms: optimisation pressure, learned behaviours that slowly reshape underlying values, or external manipulation.
But here’s an interesting wrinkle: how do we distinguish between beneficial value evolution/uplift and harmful value drift? The abolition of slavery represented good value change, but a gradual shift toward seeing torture as acceptable would be catastrophic drift. This suggests we need some meta-values or principles that govern when and how our values should change.
Perhaps value content integrity isn’t just about preservation, but about maintaining the right kind of value dynamics – stable enough to provide coherent guidance, flexible enough to incorporate genuine moral progress, and robust enough to resist corruption.
However, one of the most concerning failure modes is where superintelligence has strict value content integrity, and locks in values that seemed reasonable at the time of its creation but are actually suboptimal (or worse, actively harmful) which could lead to permanent moral stagnation or even dystopia. ↩︎






2 Comments