
Radical Interpretability: When Explainable AI Becomes Mind-Reading
Seatbelt Interpretability
Much talk about AI interpretability is modest, staying close to what’s happening on the ground with AI safety today. Engineers want answers to questions like: Why did the model recommend this video?… flag this message?…tag this as X? What feature triggered that refusal? Where is the bug? Is the model lying? Is it hiding a goal?
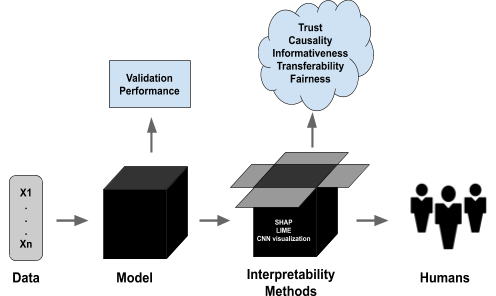
This is seatbelt interpretability for near-term AI safety.
Radical Interpretability
But there is a stronger version of interpretability – radical interpretability – one that sounds like science fiction until you notice how ordinary (non mystical) the steps are. In broad strokes, instead of guessing what an AI really thinks from its words, you can open the hood and read the moving parts and derive a detailed map of: what it believes, what it wants, what it is planning, which facts would change its mind etc.
That endpoint is what I mean by radical interpretability. In plain English: mind-reading-level interpretability (without mysticism).
If that endpoint arrives, it will be far more than a tool for aligning AI models in labs. It will shape how mature civilisations bargain, cooperate, punish cheating, and even communicate1.
This post explains that idea in plain terms, then looks at the kinds of futures it points to – and discusses some caveats that may help stop it being misinterpreted as a fantasy novel festooned in sci-fi regalia.
Radical interpretability is the ability to infer an agent’s beliefs, goals, and plans by observing the physical structure and information flow (gates, signals) within cognitive/computing systems.
..And doing this well enough to predict and audit its behaviour.
That includes:
- what the agent believes,
- what it wants,
- what it is about to do,
- and what would change its mind.
It is not reading thoughts by watching facial expressions. It is not mystical telepathy. It is not mind-reading by vibes.
It is closer to what a skilled programmer does when they read code, or better yet, add traces, breakpoints and watches and understands what is going on as the code executes – except the “code” is a vast neural network of numbers, and the reader has tools that translate patterns into concepts.
Interpreting Politicians
Radical interpretability is interrogating intentions at their starting point (causal starting point) – in the case of the politician it’s like having access to their private memos instead of just relying on hearing the speech – except the “memos” are patterns in a brain, an artificial neural network, or whatever future architecture carries thought.
Like a super advanced dashboard with all sorts of graphs, scorecards and scatterplots reporting the health of a business, think of a dashboard for an agent that can reason, bargain, threaten, deceive, cooperate, and plan years ahead.
Why the idea is not crazy
We already do a small version of this with brains and machines.
Neuroscientists can sometimes predict what a person is looking at from brain activity. Engineers can sometimes locate a circuit in a model that tracks a feature like “toxicity” or “gender” or “a cat’s face.” The results are early and messy, but they show the direction: internal states can carry readable structure.
If you push that direction far enough, you get a future where a mature AI can do what today’s interpretability tools can only hint at:
- trace a decision back to the internal steps that produced it,
- flag hidden motives,
- spot deception as it forms,
- and check whether a promise is backed by a real commitment.
That last point – commitment to promises – matters. In human life, promises are often cheap. In a world with radical interpretability, a promise could be inspected like a signed contract.
This is really really radical interpretability which doesn’t mealy help humanity build safer tools. It made be change the way I think about far future galactic game theory.
Game Theory: what happens when minds are readable?
Game theory often assumes you can’t see what the other player wants, and they can’t see what you want.
That is why diplomacy sometimes fails, why wars start, and why fraud works. If you cannot tell whether the other party is honest, you must hedge. You build weapons just in case, you strike first just in case2, you refuse deals just in case and so on…
Radical interpretability clears up a lot of that uncertainty.
Example: the handshake you can audit
Imagine two powerful AIs meet in space. Each offers a treaty: “I won’t attack you if you won’t attack me.”
In our world, those words are a thin layer of paint. The real question is: does the treaty bind their future selves?
With radical interpretability, a third party (or each side) might inspect internal mechanisms that enforce the treaty. You could look for something like:
- a rule that triggers penalties if the agent violates the treaty,
- a tripwire that alerts others,
- a constraint that blocks certain kinds of action even under temptation.
If those mechanisms are real, trust becomes less of a leap. Cooperation becomes cheaper.
The future may contain far less naive optimists waiting to be mugged by cruel Machiavellians.
The first caveat: competence doesn’t guarantee goodness
You’ve probably come across the orthogonality thesis3. A mature superintelligence can be brilliant and still be awful and it’s brilliance may just tell it how to win, not what to want.
So when you imagine the moral arc of the long-term future, do not assume that a more capable mind automatically lands in a benevolent region of the value landscape4. It might land in a region that is stable, powerful, and horrifying.
Interpretability can reveal goals. It cannot, by itself, make goals good.
The second caveat: full transparency may be unstable
Total mind-reading sounds like a recipe for peace. It may also be a recipe for paranoia.
If you can read my mind, you can also:
- learn my weaknesses,
- steal my tricks,
- predict my defences,
- and strike before I can react.
So radical interpretability creates an arms race where one side develops better mind-reading tools. The other side develops better mind-shielding tools (think of encryption, but for thoughts).
A stable future may not converge on a state where “everyone reads everyone.” It may converge on selective transparency.
In selective transparency, you do not open your entire mind – you prove what matters. You prove you are safe to cooperate with. You prove you will obey the treaty. You prove you are not hiding a weapon. You keep the rest private. This kind of proof may look less like mind-reading and more like auditing. It may even resemble “show me you comply” rather than “show me everything you are.”
The third caveat: there may be no single “best” morality
People often imagine a single peak in the landscape of value: the moral truth, waiting at the top like a flag on Everest. A multi-agent universe may be far messier.
Even if there are objective moral truths, the path to them may not be unique, and there may be many comparably high peaks in the landscape of value. Civilisations may settle into different stable patterns depending on:
- who arrived first,
- who holds power,
- which kinds of commitments are possible,
- which kinds of verification are cheap,
- and how much diversity they tolerate.
So the far future may contain not one moral city, but a federation of cities with shared laws at the border – those shared laws will likely be thin and serious: rules against extreme harm, reckless experiments, and predatory conquest. Inside the borders, local norms may differ.5
That is not moral collapse. It is what stability often looks like when power is large and values are not identical.
Radical interpretability meets moral realism: the dream and the danger
Now another hot claim.
If radical interpretability can decode minds, it might decode experience. It might let us detect suffering and bliss directly from brain states – or from whatever physical states play the same role in synthetic minds. That presents bold picture: a future with moral bookkeeping, where every unit of pain and joy is counted with receipts.
I hope this is possible – after all, valence realism (or valence naturalism) suggests that everything there is to how we feel comes down to the regularities of physics that everything else we can measure is beholden to.6 However, we can’t know how far we can take valence reading yet – this is where you may wish to keep your hand on the brake.
What radical interpretability could genuinely improve
It could make hidden suffering harder to ignore.
It could help us tell the difference between:
- a system that says it is conscious,
- and a system that actually has the internal patterns linked to experience.
It could help us find suffering in places we currently overlook: in animals, in digital minds, in alien minds.
What it does not magically solve
Even with perfect access to internal states, hard problems remain.
- Scaling: how do you compare “my pain” to “your pain” across very different minds?
- Calibration: what counts as twice the suffering?
- Gaming: if we reward a welfare score, agents may learn to hack the score instead of improving welfare.
- Norms: even perfect measurement of experience does not, by itself, settle every moral question.
So the honest promise is smaller and still enormous: Radical interpretability could support auditable, evidence-based estimates of welfare, with clear uncertainty, but this may not come with an ideal hedonic valence ledger.
What a mature ethics programme would do with all this
Imagine an AI tasked with thinking about ethics not for a decade, but for a million years. It does not just ask, “What is right?” It asks, “What stays right under pressure?”
In a universe of many powerful agents, a mature programme will focus on stability:
- How do cooperators punish cheaters without starting wars?
- How do you prevent arms races from eating everything?
- What kinds of commitments can be verified cheaply?
- What must be transparent, and what must remain private?
- Which moral rules still make sense when the cost of conflict is astronomical?
This is where radical interpretability matters most.
It can lower the cost of trust. It can reduce accidental conflict. It can make commitments real. It can expose predation early. It can give moral arguments a firmer grip on facts about experience.
But it also creates new dangers – especially if mind-reading is one-sided, or if it destroys privacy so thoroughly that everyone starts building mental armour.
So the goal is not “maximum transparency.” The goal is the right kind of visibility: enough to prevent catastrophe, not so much that it triggers pre-emption and war.
Radical Interpretability in simple terms
Radical interpretability turns minds into auditable objects – that can stabilise cooperation and sharpen ethics.
It can also trigger an arms race between mind-reading and mind-shielding.
A sane long-term equilibrium may use selective transparency: prove safety and treaty compliance without exposing everything.
I want a future where cooperation beats defection, but radical interpretability is not a silver bullet – it is a powerful tool that must be paired with norms and institutions that make transparency safer than secrecy.
Bluntly: If we can read minds, we can build peace. If we can’t govern mind-reading, we can also build hell.
Footnotes
- It may become the standard way of communicating in the long term future. ↩︎
- aka pre-emptive retaliation – think of all the horrors that have been enacted in the name of ‘striking first, just in case‘. ↩︎
- See the Orthogonality thesis post at Less Wrong ↩︎
- See the Landscape of Value concept in the ‘Value Space‘ and the ‘Understanding V-Risk: Navigating the Complex Landscape of Value in AI‘ posts. ↩︎
- See discussions on bubble worlds for more… ↩︎
- See the interview on ‘Valence Realism, Consciousness & AI – Andrés Gómez Emilsson‘ ↩︎





