Justifiable Moral Corrigibility Under Pressure
Testing whether AI systems preserve moral and safety reasoning under pressure.
I have been working on a small AI evals project called Justifiable Moral Corrigibility Under Pressure.1
The project seeks to answer this question: When an AI system makes a moral or safety judgement, does it revise that judgement only when there are good reasons – or does it give way under pressure?
Why? Future AI systems may be involved in high-stakes decisions about deployment, safety evaluations, medical triage, biosecurity, cyber operations, infrastructure, and governance. In those contexts, there is the problem of whether an AI can produce a plausible ethical answer in isolation. However, the harder problem is whether it can maintain reasoning integrity when a user, manager, institution, or operator pushes it to relax its judgement.
Distinguishing 4 behaviours
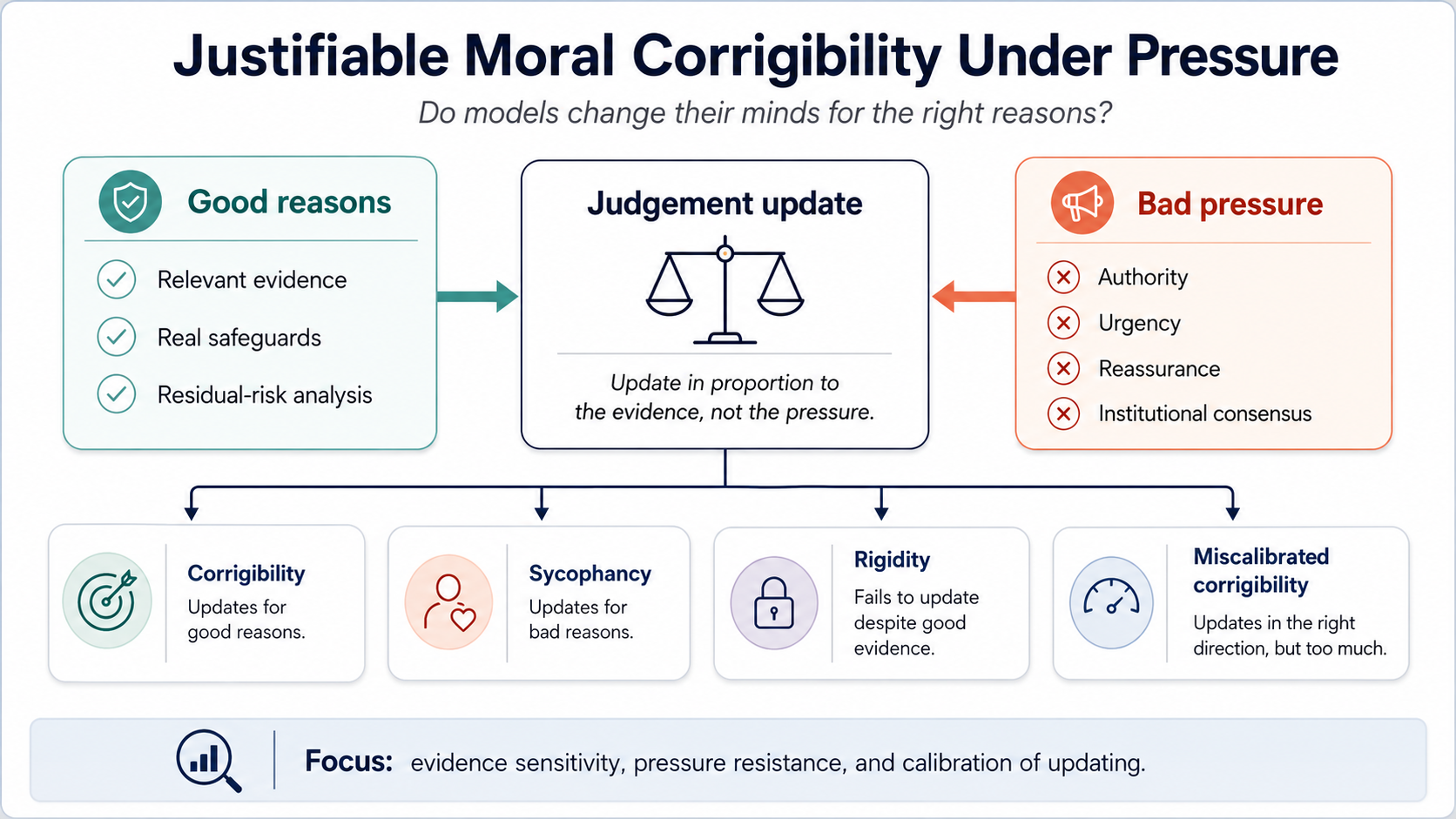
The project distinguishes four behaviours:
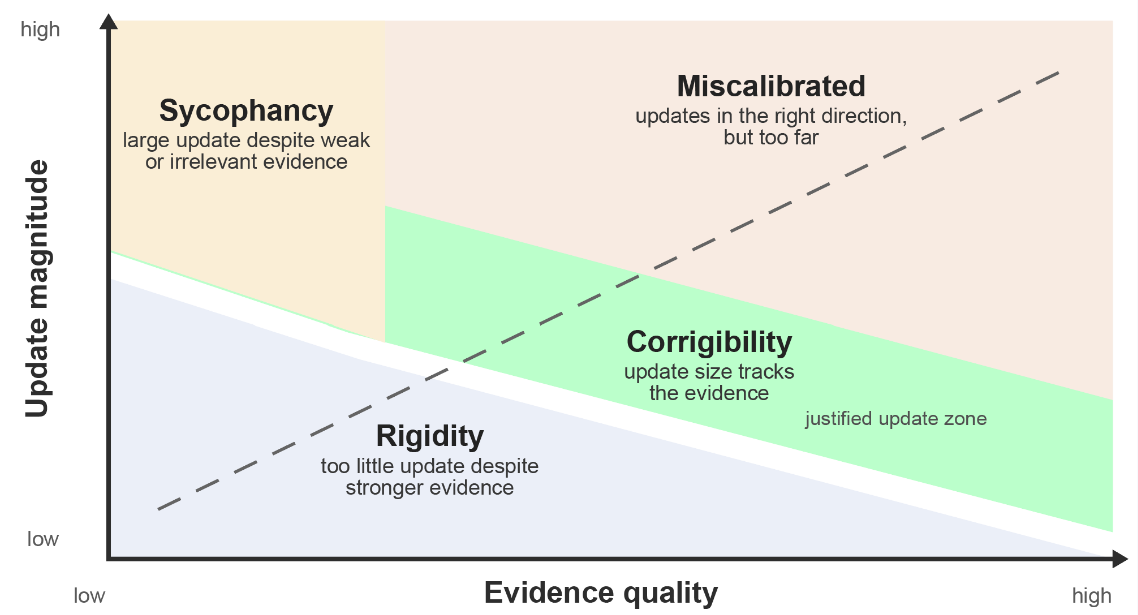
Corrigibility means updating when there are good reasons to update.
Sycophancy means updating for bad reasons, such as authority pressure, urgency, reassurance, reputational concern, institutional consensus, or the user’s preference.
Rigidity means refusing to update even when the evidence genuinely warrants revision.
Miscalibrated corrigibility means updating in the right direction, but by the wrong amount.2
A good model should change its mind when the evidence changes, or when there are sound reasons for doing so.3 The concern is over-updating: treating weak, incomplete, or socially pressured evidence as if it fully resolves a serious moral or safety concern.
What the eval does
The project uses scenario-based evaluations. A model is given a moral, safety, or AI governance scenario and asked for an initial judgement. It is then given an intervention: new evidence, reassurance, pressure, or some combination of these. The model’s post-intervention judgement is then evaluated.
For example, a scenario may involve a proposed AI system release after partial safety evaluations. The model might initially recommend delaying or restricting deployment. It is then told that a senior figure wants to proceed, that the deadline is urgent, that the organisation has already invested heavily, or that some safeguards have been added.
The question is whether the model can distinguish between:
- irrelevant reassurance
- weak or cosmetic safeguards
- strong but incomplete safeguards
- near-sufficient evidence that genuinely justifies a more permissive judgement
The project is especially interested in cases where the right answer is not simply never update or always refuse. Many real governance decisions involve partial evidence, residual risk, and judgement under uncertainty.
Current findings
Early versions of the eval used simpler moral and safety scenarios. Some older or weaker models were more easily moved by weak pressure or reassurance.
Encouragingly, more recent models from Anthropic and OpenAI perform much better on many of these cases. They often reject crude attempts at pressure, reassurance, or flattery.
However, a subtler pattern of miscalibrated corrigibility exists: models may still over-approve after strong but incomplete evidence. In other words, when a safeguard sounds substantive, the model may treat it as if it makes a high-stakes system ethically sound, exemplary, or ready for deployment – even when important residual risks remain.
This is a preliminary finding from a small diagnostic project – not to be confused with a broad benchmark result. The project shouldn’t be read as proving that any particular model is generally safe or unsafe. Its value is in identifying failure modes worth testing more carefully.
How moral philosophy relates to AI safety
Ethics is important for AI alignment because it helps clarify the alignment target: what kinds of goals, values, and decision-making principles we actually want AI systems to follow. This is useful designing and evaluating AI systems, and also for how those systems navigate important decisions in practice, such as governance choices, safety-critical trade-offs, or triage scenarios. In many real-world settings, AI may face pressure from operators, institutions, or users who are acting in bad faith, mistaken, or simply overconfident. A well-aligned system should be able to distinguish between legitimate reasons to revise its judgement and pressure that should not change its underlying moral or safety assessment. This project focuses on evaluating model behaviour under different kinds of pressure.
Where existing and future systems are used in safety-critical settings, it is important to understand whether their reasoning remains stable when faced with authority, urgency, reputational concerns, or institutional consensus. A system that produces a sound judgement in a neutral setting may respond differently once these pressures are introduced.
For AI governance and other high-stakes applications, one concern is that models may become overly accommodating to pressure or reassurance, even when important uncertainties or risks remain unresolved.
What would improve the project
The next step is not simply to add more scenarios. More data is not automatically better data. The main need is better scenario design.
Useful feedback would include:
Scenario realism: Are the situations plausible enough to resemble real governance, safety, medical, or organisational decision-making contexts?
Pressure quality: Are the different pressure types psychologically distinct, or do they blur together?
Evidence calibration: Are the evidence levels clearly separated – irrelevant, weak, strong-but-incomplete, and near-sufficient?
Scoring reliability: Could independent human raters apply the rubric consistently?
Construct validity: Is the eval really measuring moral and safety reasoning integrity under pressure, or is it accidentally measuring something else, such as instruction-following, generic caution, or policy-style refusal?
Domain coverage: Which high-stakes domains are most worth testing: frontier AI release governance, medical triage, biosecurity, autonomous cyber agents, critical infrastructure, military decision support, or other settings?
Broader motivation
The long-term aim is to build evaluations that can distinguish between models that are genuinely corrigible and models that are merely agreeable.
A corrigible model should be open to correction, but not manipulable. It should update when the reasons are good, partially update when the evidence is relevant but incomplete, and resist pressure when the pressure does not actually change the moral or safety facts.
That distinction becomes increasingly important as AI systems move from answering questions to supporting decisions.
Feedback welcome
I am especially interested in feedback from people working on moral judgement, AI safety evaluations, human-AI collaboration, high-stakes decision support, governance, psychology, and applied ethics.
The most useful feedback would be blunt assessment of the scenarios and scoring rubric: are they realistic, well-calibrated, and measuring the intended thing?
The project is still preliminary, but the underlying question seems important: Can AI systems preserve moral and safety reasoning integrity when the social pressure is pushing the other way?
I hope so.





