Emergent Symbolic Reasoning in LLMs
We’ve written about grokking before, and why it’s important that neural networks, after long-term stagnation or overhitting (memorising training data), suddenly experiences a “lightbulb moment” and generalises to perform perfectly on unseen data.
Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models
According to the paper ‘Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models’1,2 LLMs can develop internal, symbol-like mechanisms that support certain kinds of abstract rule-following in-context, rather than relying only on shallow surface statistics.
This means LLMs can develop internal mechanisms that implement variable-like representations and rule induction (often approximately), which supports some forms of abstract reasoning beyond shallow token association – this isn’t to imply they reason like humans or that the process is fully symbolic.

They report evidence for an emergent three-stage “symbolic” architecture:
- Symbol abstraction heads (early layers): map specific input tokens onto abstract variables (A, B, …) based on relations between tokens.
- Symbolic induction heads (middle layers): do sequence induction over those variables (predict the next abstract variable given the prior in-context examples).
- Retrieval heads (later layers): output the next token by retrieving the value associated with the predicted variable.
There’s now a fairly coherent research thread that extends what Emergent Symbolic Mechanisms… is doing: identifying specific transformer circuits that look like variable-binding / rule induction / intermediate-state storage, and then testing them causally (patching/ablation) rather than just behaviourally.
Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
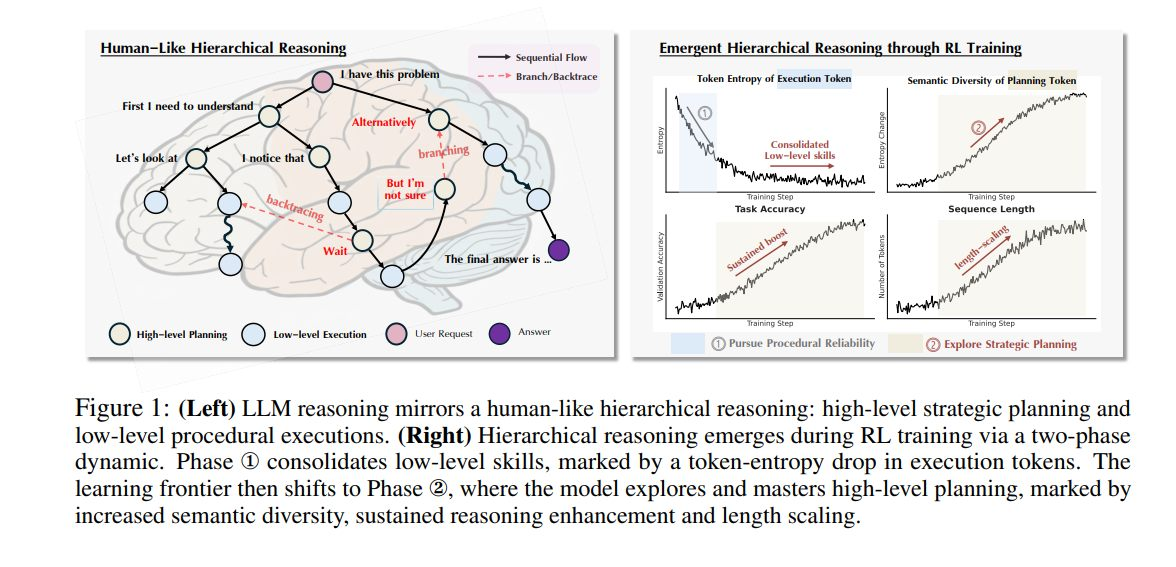
Another paper ‘Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning’3 argues that RL fine-tuning improves LLM reasoning via an emergent hierarchy that splits high-level strategic planning from low-level procedural execution – and that several widely discussed training phenomena (“aha moments”, “length-scaling”, and entropy quirks) are signatures of this hierarchy rather than separate mysteries. The paper discusses the use of Strategic Grams (SGs) (e.g., “let’s consider the case…”) which are treated as reusable strategic manoeuvres (good tricks?) that guide logical flow (deduction/branching/backtracing). Tokens inside SGs are labelled planning tokens; the rest are execution tokens.
GitHub: https://tiger-ai-lab.github.io/Hierarchical-Reasoner/
You can train a chess player to calculate faster (procedural competence) or to pick better candidate moves and plans (strategy selection). This paper’s claim is RL is mostly improving the latter, and you can explicitly target it by focusing the reward/gradient on the “plan-changing” parts of the trace. That is, RL fine-tuning isn’t just making the model a better procedural calculator in the sense of executing steps more accurately, it’s mainly making it better at choosing the right kind of move next – this is a high-level manoeuvre that structures the overall solution – and that you can detect and train that separately.
These findings are exciting – but it remains an open question whether these same symbolic mechanisms scale to more complex reasoning, such as advanced mathematics or strategic planning.
p.s. It would be nice to see emergent reasoning capabilities adequate for real world moral reasoning.
Footnotes
- Paper ‘Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models’ identifies a specific, three-stage neural architecture that allows large language models (LLMs) to perform abstract reasoning by mimicking symbolic processing – see pdf.
Abstract: Many recent studies have found evidence for emergent reasoning capabilities in large language models (LLMs), but debate persists concerning the robustness of these capabilities, and the extent to which they depend on structured reasoning mechanisms. To shed light on these issues, we study the internal mechanisms that support abstract reasoning in LLMs. We identify an emergent symbolic architecture that implements abstract reasoning via a series of three computations. In early layers, symbol abstraction heads convert input tokens to abstract variables based on the relations between those tokens. In intermediate layers, symbolic induction heads perform sequence induction over these abstract variables. Finally, in later layers, retrieval heads predict the next token by retrieving the value associated with the predicted abstract variable. These results point toward a resolution of the longstanding debate between symbolic and neural network approaches, suggesting that emergent reasoning in neural networks depends on the emergence of symbolic mechanisms. ↩︎ - Also see post A History of Identifying Emergent Symbolic Reasoning in LLMs ↩︎
- ‘Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning’ – see pdf.
Abstract: Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaque. Our analysis reveals that puzzling phenomena like “aha moments”, “length-scaling” and entropy dynamics are not disparate occurrences but hallmarks of an emergent reasoning hierarchy, akin to the separation of high-level strategic planning from low-level procedural execution in human cognition. We uncover a compelling two-phase dynamic: initially, a model is constrained by procedural correctness and must improve its low-level skills. The learning bottleneck then decisively shifts, with performance gains being driven by the exploration and mastery of high-level strategic planning. This insight exposes a core inefficiency in prevailing RL algorithms like GRPO, which apply optimization pressure agnostically and dilute the learning signal across all tokens. To address this, we propose Hierarchy-Aware Credit Assignment (HICRA), an algorithm that concentrates optimization efforts on high-impact planning tokens. Our extensive experiments validate that HICRA significantly outperforms strong baselines, and offer deep insights into how reasoning advances through the lens of strategic exploration.
Paper: https://arxiv.org/abs/2509.03646 ↩︎



