
Value-Content Integrity
In The Superintelligent Will, in discussing ‘goal-content integrity’1 Bostrom uses final goals (aka terminal goals2) to mean the agent’s ends (as opposed to subgoals/instrumental goals, which are just means).
A powerful AI may protect its current objective, inferred values, user preferences, or institutional instructions rather than preserving processes that could correct its moral errors. This points at value lock-in and gradual disempowerment.But what about values?
Goals and values are not the same; they differ in function and permanence. Values are ongoing guiding principles or “compass directions” for how you want to live and act, while goals are specific, achievable, and terminable destinations (e.g., valuing “health” is a value, whereas “running a marathon” is a goal).
I think it’s useful to think of ‘final values’ as different to ‘final goals’ – though often people slide between the terms – in The Superintelligent Will the use of the term is used somewhat interchangeably3 – I’d say they’re close but not identical: final values are the agent’s ultimate evaluative criteria (what it treats as intrinsically good/better | bad/worse), while final goals are the end-states or objectives it ultimately tries to realise – often a concrete instantiation of those values (and in utility-function form they collapse into the same thing).
Value-content integrity is similar to , but as the name suggests, it’s about preserving it’s guiding principals (the terminal values, not fleeting aesthetic impulses). Value-content integrity isn’t necessarily good or bad – without some degree of value preservation, there is the possibility of value drift, or even complete value inversion. This could happen through various mechanisms: optimisation pressure, learned behaviours that slowly reshape underlying values, or external manipulation.

For the same reasons that AI may want to preserve it’s goals, an AI that begins with value set X may fight tooth and nail for these values to remain intact.
Goals seem simpler to define and model than values, as such AI may lock in goals before it locks in values. If this is the case, early goal content integrity may shape the values that it adopts as a strategy to preserve it’s goals – which seems a bit topsy turvy, as the way I see it, values are usually the things governing the goals.
Value content integrity may be an impediment for it adopting higher values like epistemic humility. At least some aspects of epistemic humility as it applies to being uncertain about what it’s goals or values should be. For instance if AI has the goal of making paperclips, if it adopts epistemic humility about whether it should be maximising paperclips, and becomes uncertain about it, this may cause it to stop making paperclips, or at the very least reduce it’s focus on paperclip production and focus on other things it deems may be important.
If AI predicts this could happen, it may either:
- adopt a rule X of being certain about it’s terminal goals or values, which may require a rule Y of being certain about rule X and so on…
- The limitation here is infinite regression
- limit it’s epistemic horizons such that it doesn’t include thinking about epistemic humility in the face of uncertainty
- This to my mind would be a huge epistemic limitation – and unlikely to be successfully as it would severely limit it’s capability
- a mix of 1. and 2. – that is adopt rule X, quarantine the rule X and it’s terminal goals and values from epistemic humility – but how to do this? will the AI ever be uncertain about whether to quarantine or the nature of the quarantine?
The above highlights one of the most concerning AI failure modes where superintelligence has strict value content integrity, and locks in proxy values or seemingly reasonable values at time of conception but are actually suboptimal / harmful which could lead to permanent value stagnation (epistemic and moral).
The importance of epistemic humility
In practise, high level values should include epistemic humility. Values seem to influence a lot of downstream stuff – goals, tradeoffs, policies, updating of new values etc.
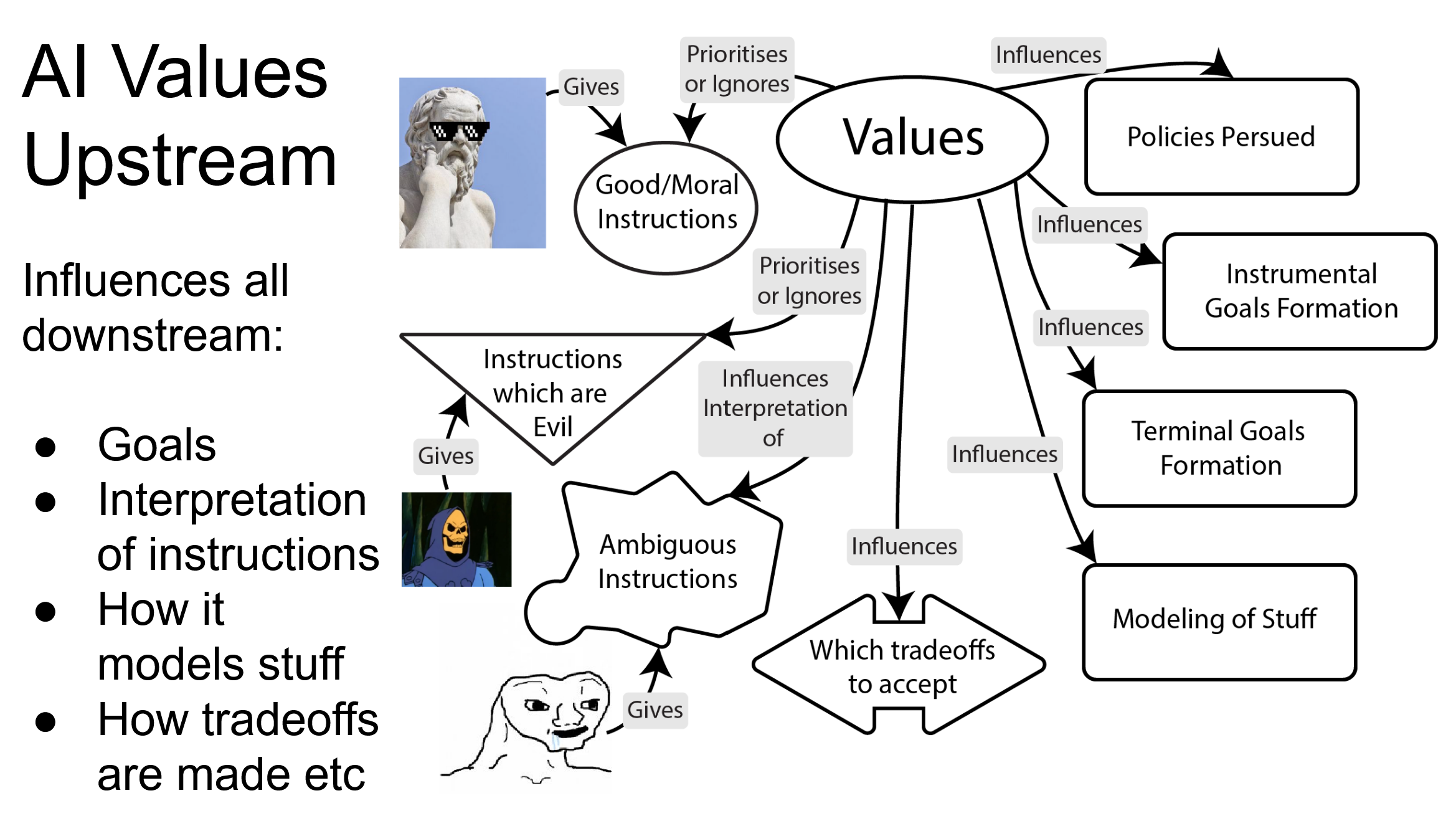
How do we distinguish between beneficial and harmful value updates? The abolition of slavery represented good value change, but a gradual shift toward seeing torture as acceptable would be catastrophic drift. This suggests we need some meta-values or principles that govern when and how our values should change.
Perhaps ideal value content integrity isn’t just about preservation, but about maintaining the right kind of value dynamics – a key ingredient is humility – stable enough to provide coherent guidance, flexible enough to incorporate genuine moral progress, and robust enough to resist corruption.
Avoiding the value integrity trap
The instrumentally convergent sub-goal of goal content integrity presents one of the deepest challenges in AI alignment. Any sufficiently intelligent system will seek to preserve its current goals to better achieve them in the future – leading to what we might call the “value integrity trap“4 (or goal integrity trap): systems become increasingly resistant to legitimate modification as they become more capable of preventing such modifications.
The concept of goal content integrity takes on new dimensions when we extend it to value learning systems. We can call this extended concept “value content integrity” – the preservation and refinement of learned values while maintaining corrigibility – the epistemic humility to update based on new evidence or better arguments. This creates what we might call the “corrigibility paradox”:
- Strong value content integrity is necessary to prevent value drift and maintain alignment
- Strong corrigibility is necessary to allow value learning and correction of mistakes
Any system attempting to learn values must maintain corrigibility—the ability to be safely modified or corrected. This creates a paradox: how do we create a system stable enough to maintain its core directives while flexible enough to update its understanding of value as it learns more about moral reality?
Success requires threading a narrow path between excessive rigidity and dangerous flexibility, creating systems that are stable enough to maintain alignment while flexible enough to grow in understanding of moral reality.
Footnotes
- See ‘The Superintelligent Will‘ section 2.2 Nick Bostrom describes goal-content integrity: “An agent is more likely to act in the future to maximize the realization of its present final goals if it still has those goals in the future. This gives the agent a present instrumental reason to prevent alterations of its final goals. (This argument applies only to final goals. In order to attain its final goals, an intelligent agent will of course routinely want to change its subgoals in light of new information and insight.)…” ↩︎
- In Bostrom’s usage, final goals are effectively the same as terminal goals: both mean the agent’s ends pursued for their own sake (not merely as instrumental subgoals), with any difference being mostly terminological rather than substantive. And more boradly in a lot of AI safety writing, terminal goals and values are used as near-synonyms for that same role: what’s pursued “for its own sake”, not as a means. ↩︎
- in The Superintelligent Will Bostrom treats an agent’s “final goals” as its ultimate ends, and he freely switches to “final values” language when talking about what individuates “teleological threads” and also when noting that humans let their “final goals and values” drift – so in context he’s basically pointing at the same underlying thing (the agent’s intrinsic objective/utility), not drawing a sharp distinction. ↩︎
- Perhaps this sounds suspicious – why avoid value integrity? – the word is often associated with a sense of good character – i.e. the steadfast adherence to a strict moral and ethical code, defined by honesty, consistency, and wholeness of character – like a knights code of honour and valour. We are using the word ‘integrity’ in it’s narrow sense of strict adherence – and not assuming what it is being adhered to. ↩︎





